DALL‑E, an artificial intelligence system that generates viable-looking art in a variety of styles in response to user supplied text prompts, has been garnering a lot of interest since it debuted this spring.
It has yet to be released to the general public, but while we’re waiting, you could have a go at DALL‑E Mini, an open source AI model that generates a grid of images inspired by any phrase you care to type into its search box.
Co-creator Boris Dayma explains how DALL‑E Mini learns by viewing millions of captioned online images:
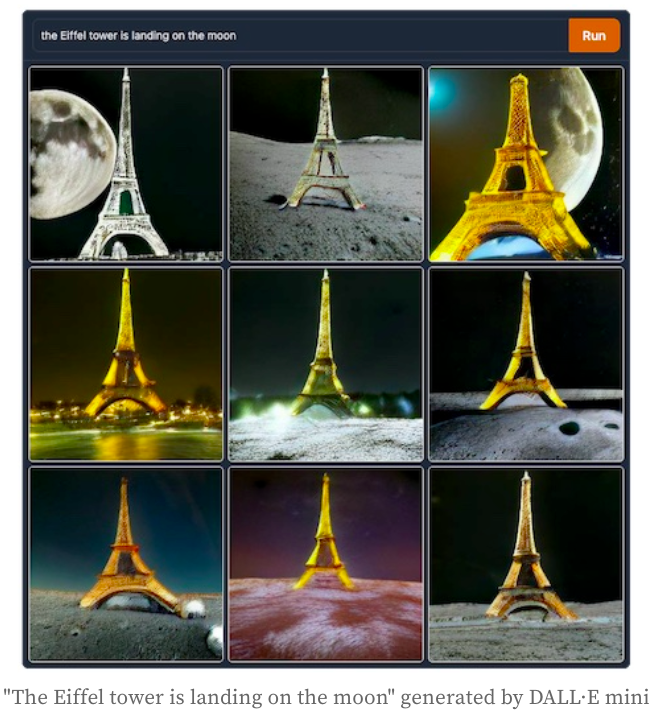
Some of the concepts are learnt (sic) from memory as it may have seen similar images. However, it can also learn how to create unique images that don’t exist such as “the Eiffel tower is landing on the moon” by combining multiple concepts together.
Several models are combined together to achieve these results:
• an image encoder that turns raw images into a sequence of numbers with its associated decoder
• a model that turns a text prompt into an encoded image
• a model that judges the quality of the images generated for better filtering
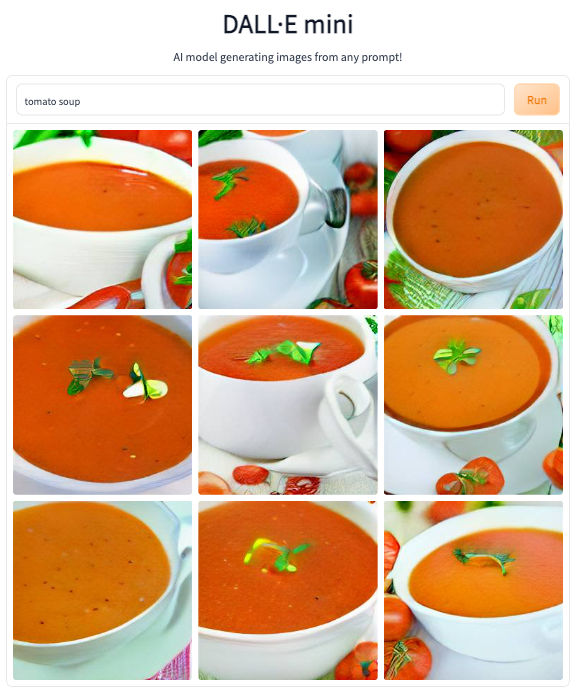
My first attempt to generate some art using DALL‑E mini failed to yield the hoped for weirdness. I blame the blandness of my search term — “tomato soup.”
Perhaps I’d have better luck “Andy Warhol eating a bowl of tomato soup as a child in Pittsburgh.”
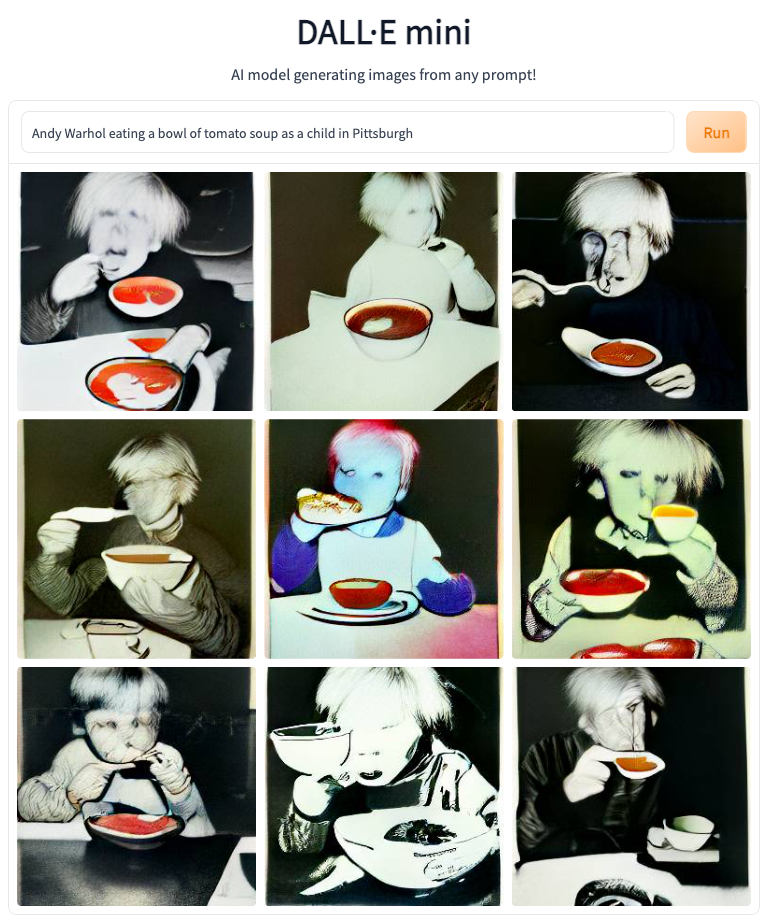
Ah, there we go!
I was curious to know how DALL‑E Mini would riff on its namesake artist’s handle (an honor Dali shares with the titular AI hero of Pixar’s 2018 animated feature, WALL‑E.)
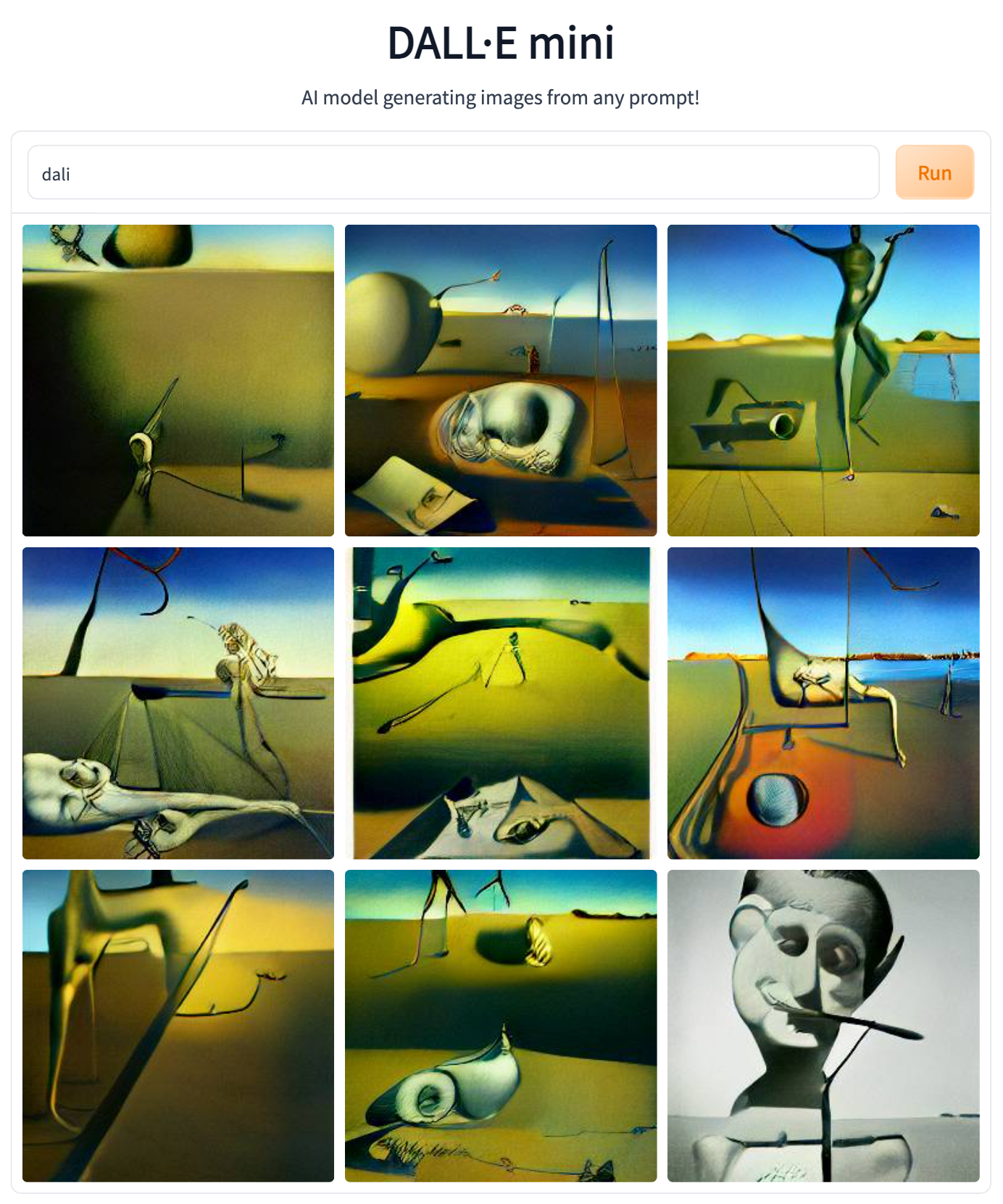
Hmm… seems like we’re backsliding a bit.
Let me try “Andy Warhol eating a bowl of tomato soup as a child in Pittsburgh with Salvador Dali.”
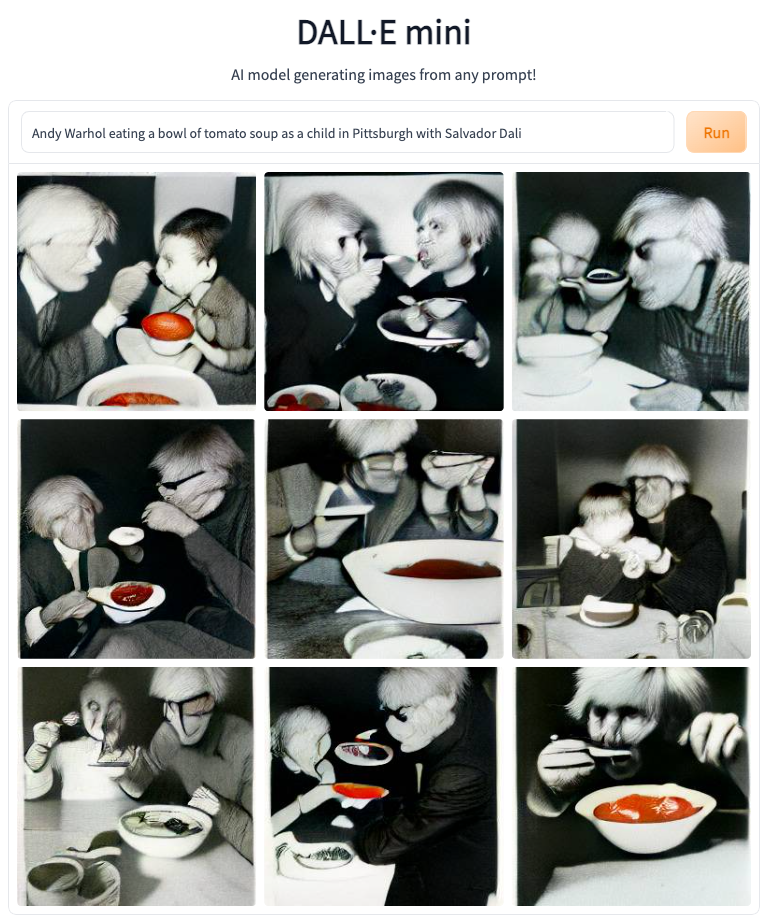
Ye gods! That’s the stuff of nightmares, but it also strikes me as pretty legit modern art. Love the sparing use of red. Well done, DALL‑E mini.
At this point, vanity got the better of me and I did the AI art-generating equivalent of googling my own name, adding “in a tutu” because who among us hasn’t dreamed of being a ballerina at some point?

Let that be a lesson to you, Pandora…
Hopefully we’re all planning to use this playful open AI tool for good, not evil.
Hyperallergic’s Sarah Rose Sharp raised some valid concerns in relation to the original, more sophisticated DALL‑E:
It’s all fun and games when you’re generating “robot playing chess” in the style of Matisse, but dropping machine-generated imagery on a public that seems less capable than ever of distinguishing fact from fiction feels like a dangerous trend.
Additionally, DALL‑E’s neural network can yield sexist and racist images, a recurring issue with AI technology. For instance, a reporter at Vice found that prompts including search terms like “CEO” exclusively generated images of White men in business attire. The company acknowledges that DALL‑E “inherits various biases from its training data, and its outputs sometimes reinforce societal stereotypes.”
Co-creator Dayma does not duck the troubling implications and biases his baby could unleash:
While the capabilities of image generation models are impressive, they may also reinforce or exacerbate societal biases. While the extent and nature of the biases of the DALL·E mini model have yet to be fully documented, given the fact that the model was trained on unfiltered data from the Internet, it may generate images that contain stereotypes against minority groups. Work to analyze the nature and extent of these limitations is ongoing, and will be documented in more detail in the DALL·E mini model card.
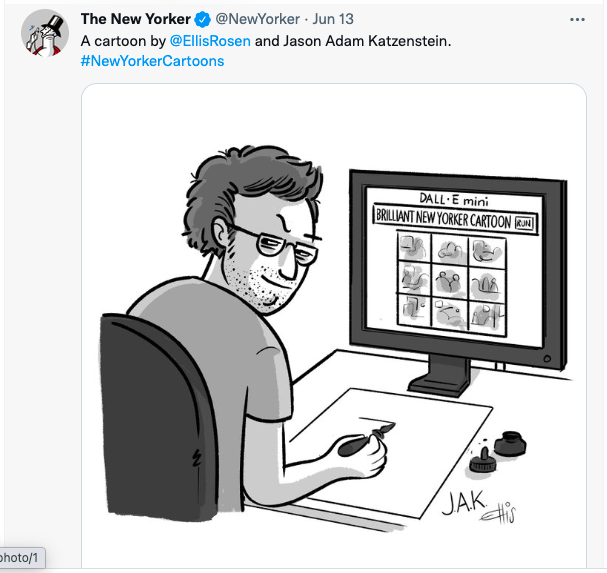
The New Yorker cartoonists Ellis Rosen and Jason Adam Katzenstein conjure another way in which DALL‑E mini could break with the social contract:
And a Twitter user who goes by St. Rev. Dr. Rev blows minds and opens multiple cans of worms, using panels from cartoonist Joshua Barkman’s beloved webcomic, False Knees:

Proceed with caution, and play around with DALL‑E mini here.
Get on the waitlist for original flavor DALL‑E access here.
Related Content
- Ayun Halliday is the Chief Primatologist of the East Village Inky zine and author, most recently, of Creative, Not Famous: The Small Potato Manifesto. Follow her @AyunHalliday.